一、
学号:2017****07223 姓名:许乾坤 码云: 二、 程序分析# filename: word_freq.py# 阅读注释,在所有pass处删除pass,添加代码from string import punctuationdef process_file(dst): # 读文件到缓冲区 try: # 打开文件 f = open(dst) except IOError as s: print (s) return None try: # 读文件到缓冲区 bvffer = f.read() except: print ("Read File Error!") return None f.close() return bvfferdef process_buffer(bvffer): if bvffer: word_freq = {} # 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq for item in bvffer.strip().split(): word = item.strip(punctuation+' ') if word in word_freq: word_freq[word] += 1 else: word_freq[word] = 1 return word_freqdef output_result(word_freq): if word_freq: sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) for item in sorted_word_freq[:10]: # 输出 Top 10 的单词 print(item)if __name__ == "__main__": import argparse parser = argparse.ArgumentParser() parser.add_argument('dst') args = parser.parse_args() dst = args.dst bvffer = process_file(dst) word_freq = process_buffer(bvffer) output_result(word_freq) 三、性能分析结果及改进情况
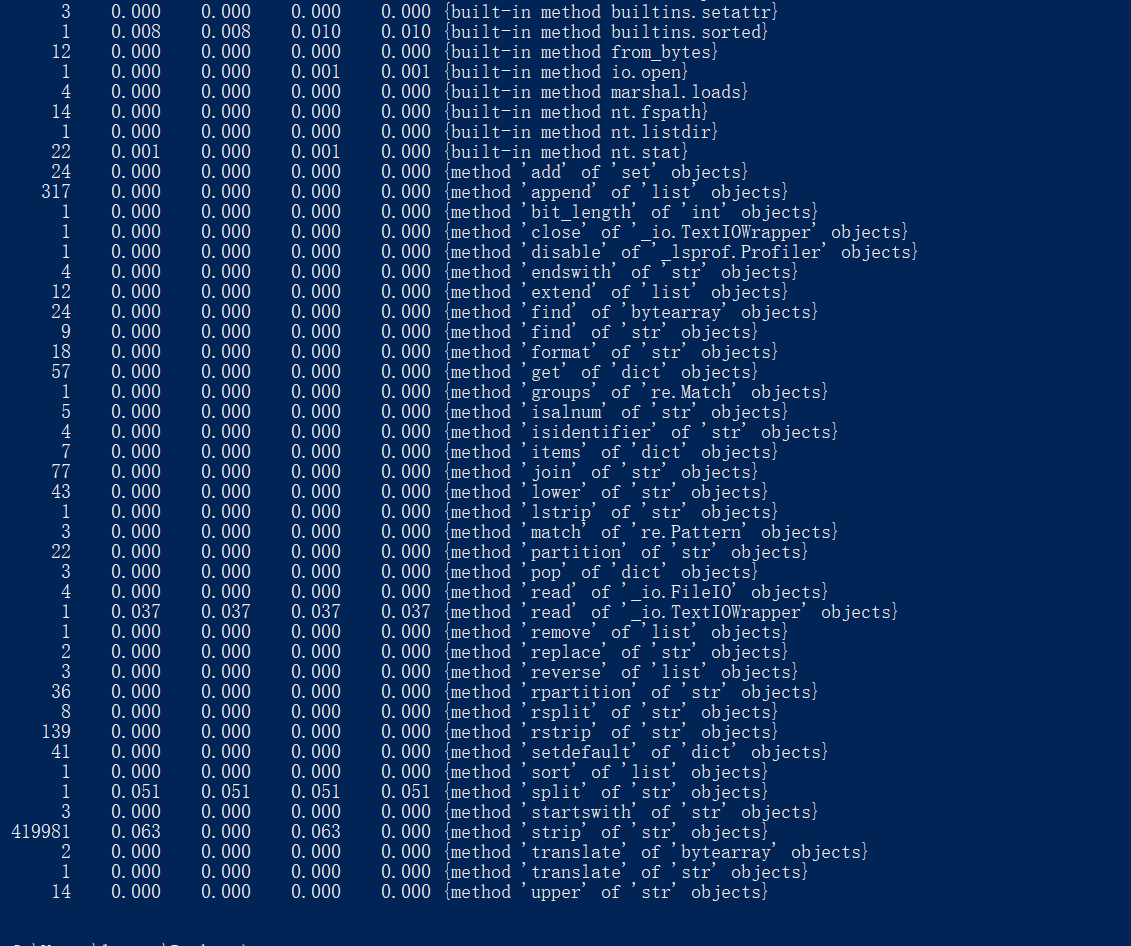
(1)指出了正确的执行次数最多的代码和执行时间最长的代码
执行次数最多的代码

执行时间最长的代码

(2)给出改进优化方法,根据方法的正确性以及语言描述质量给分
答:改进界面、显示优化,使结果明确展现
(3)给出改进代码
#定义一个getstr类,对结果输出格式进行定义def getstr(word,count,allwordnum): countstr=word+'----'+str(count)+'----'+str(allwordnum) return countstrprint('出现单词:'+word.1just(18)+'出现次数:'.1just(0)+str(cnt).1just(10)+'文章单词总数:'.1just(0)+str(allwordnum))outdata.write(getstr(word,cnt,allwordnum)+'\n') 四、运行结果
 五、总结和反思 程序设计基础很差,需要极大的提升,经过此次任务我发现我对python不懂得还有很多虽然同学帮助并且讲解但还是不熟练还需要多加练习
五、总结和反思 程序设计基础很差,需要极大的提升,经过此次任务我发现我对python不懂得还有很多虽然同学帮助并且讲解但还是不熟练还需要多加练习